2026년 AI 기술의 한계를 돌파할 핵심 열쇠로, 엔비디아의 차세대 AI 칩에 탑재될 HBM4 베라 루빈이 전 세계적인 주목을 받고 있습니다. HBM4 베라 루빈이란, 엔비디아의 차세대 AI 플랫폼 '베라 루빈(Vera Rubin)'에 탑재되는 6세대 차세대 고대역폭 메모리(HBM4) 기술을 의미합니다. 이는 인공지능(AI) 연산의 가장 큰 걸림돌이었던 메모리 병목 현상 해결을 위한 혁신적인 솔루션으로 평가받고 있습니다. 이 기술은 기존 블랙웰 아키텍처 대비 4~5배 높은 효율을 목표로 하며, AI가 처리해야 하는 데이터의 양을 감당하고도 남아 처리 속도를 극적으로 끌어올릴 잠재력을 지니고 있습니다. AI 모델이 기하급수적으로 커지면서 기존 메모리 기술로는 감당할 수 없는 데이터 처리 요구량이 발생했습니다. 이로 인해 최신 그래픽 처리 장치(GPU)가 제 성능을 발휘하지 못하는 '메모리 병목'이 AI 산업 발전의 심각한 문제로 대두되었습니다. GPU가 아무리 빨리 계산할 준비를 마쳐도, 필요한 데이터가 제때 도착하지 않으면 무용지물이 되기 때문입니다. HBM4는 바로 이 문제를 정면으로 돌파하기 위해 탄생했습니다. 본 글에서는 HBM4 기술의 핵심 개념부터 베라 루빈 플랫폼과의 강력한 시너지, AI 가속기에 미치는 영향, 그리고 시장의 미래 전망까지 심층적으로 분석하겠습니다. 독자들이 이 글 하나만으로 HBM4 베라 루빈에 대한 모든 핵심 정보를 얻고, 다가올 기술 혁명을 명확히 이해할 수 있도록 안내하는 것이 이 글의 목표입니다. 이것은 단순한 부품의 업그레이드가 아니라 AI 시대의 컴퓨팅 구조를 근본적으로 바꾸는 거대한 변화의 시작점입니다.
목차
- 서론: AI 시대의 새로운 지평을 여는 HBM4 베라 루빈
- HBM4란 무엇인가: 차세대 고대역폭 메모리의 기술적 진화
- 베라 루빈 데이터 처리 속도, HBM4로 날개를 달다
- HBM4 탑재 AI 가속기: AI 연산의 패러다임을 바꾸다
- 고질적 문제, 메모리 병목 현상과 HBM4의 명쾌한 해법
- 미래 전망: HBM4 이후의 메모리 시장과 기술 발전 방향
- 결론: HBM4 베라 루빈, AI 혁신을 위한 필수불가결한 선택

1. 서론: AI 시대의 새로운 지평을 여는 HBM4 베라 루빈
2026년 AI 기술의 한계를 돌파할 핵심 열쇠로, 엔비디아의 차세대 AI 칩에 탑재될 HBM4 베라 루빈이 전 세계적인 주목을 받고 있습니다. HBM4 베라 루빈이란, 엔비디아의 차세대 AI 플랫폼 '베라 루빈(Vera Rubin)'에 탑재되는 6세대 차세대 고대역폭 메모리(HBM4) 기술을 의미합니다. 이는 인공지능(AI) 연산의 가장 큰 걸림돌이었던 메모리 병목 현상 해결을 위한 혁신적인 솔루션으로 평가받고 있습니다. 이 기술은 기존 블랙웰 아키텍처 대비 4~5배 높은 효율을 목표로 하며, AI가 처리해야 하는 데이터의 양을 감당하고도 남아 처리 속도를 극적으로 끌어올릴 잠재력을 지니고 있습니다.
AI 모델이 기하급수적으로 커지면서 기존 메모리 기술로는 감당할 수 없는 데이터 처리 요구량이 발생했습니다. 이로 인해 최신 그래픽 처리 장치(GPU)가 제 성능을 발휘하지 못하는 '메모리 병목'이 AI 산업 발전의 심각한 문제로 대두되었습니다. GPU가 아무리 빨리 계산할 준비를 마쳐도, 필요한 데이터가 제때 도착하지 않으면 무용지물이 되기 때문입니다. HBM4는 바로 이 문제를 정면으로 돌파하기 위해 탄생했습니다.
본 글에서는 HBM4 기술의 핵심 개념부터 베라 루빈 플랫폼과의 강력한 시너지, AI 가속기에 미치는 영향, 그리고 시장의 미래 전망까지 심층적으로 분석하겠습니다. 독자들이 이 글 하나만으로 HBM4 베라 루빈에 대한 모든 핵심 정보를 얻고, 다가올 기술 혁명을 명확히 이해할 수 있도록 안내하는 것이 이 글의 목표입니다. 이것은 단순한 부품의 업그레이드가 아니라 AI 시대의 컴퓨팅 구조를 근본적으로 바꾸는 거대한 변화의 시작점입니다.

2. HBM4란 무엇인가: 차세대 고대역폭 메모리의 기술적 진화
고대역폭 메모리(HBM)는 기존 그래픽카드에 사용되던 GDDR 메모리의 대역폭 한계를 극복하기 위해 탄생한 기술입니다. 여러 개의 D램 칩을 아파트처럼 수직으로 쌓아(적층) 데이터가 이동하는 거리를 획기적으로 줄이고, 데이터가 다니는 길(대역폭)을 극대화한 것이 핵심입니다. 이러한 구조 덕분에 HBM은 더 빠른 속도와 낮은 전력 소비를 동시에 달성할 수 있었습니다.
HBM4는 이러한 HBM 기술의 최신 진화형으로, 이전 세대인 HBM3 대비 데이터 전송 속도 요구치가 9Gbps에서 11Gbps 이상으로 크게 상향된 차세대 고대역폭 메모리입니다. 하지만 HBM4의 혁신은 단순히 속도 향상에만 그치지 않습니다. 더 많은 D램을 쌓아(최대 16단) 용량을 늘리고, GPU와 더욱 긴밀하게 연결하여 데이터 접근에 걸리는 지연 시간(latency)을 최소화하는 구조적 혁신까지 포함하고 있습니다. 이는 AI 모델처럼 방대한 데이터를 한 번에 처리해야 하는 작업에서 결정적인 성능 차이를 만들어냅니다.
HBM4 베라 루빈이 특별한 이유는 엔비디아의 베라 루빈 GPU와의 완벽한 통합 설계에 있습니다. 베라 루빈 GPU 한 개당 8개의 HBM4 스택이 탑재되어, 마치 하나의 칩처럼 유기적으로 작동합니다. 이는 단순히 빠른 부품을 조립하는 수준을 넘어, 시스템 전체의 데이터 흐름을 최적화하여 성능을 극한까지 끌어올리는 설계 철학의 결과물입니다. HBM3와 HBM4의 주요 기술 지표를 비교하면 그 차이를 명확히 알 수 있습니다.
| 항목 | HBM3 (기존) | HBM4 (베라 루빈) | 개선점 |
|---|---|---|---|
| 전송 속도 | 약 9Gbps | 11Gbps 이상 | 22% 이상 향상 |
| 최대 적층 수 | 12단 | 16단 이상 | 고용량 AI 모델 처리 용이 |
| 인터페이스 | 1024-bit | 2048-bit (예상) | 데이터 통로 2배 확장 |
| 전력 효율 | 기준 | 개선 (발열 관리 최적화) | 데이터센터 운영 비용(TCO) 절감 |
이처럼 HBM4는 인터페이스를 두 배로 넓혀 데이터가 오가는 길 자체를 확장했습니다. 이는 좁은 도로를 넓은 고속도로로 바꾸는 것과 같아, 훨씬 더 많은 양의 데이터를 막힘없이 처리할 수 있게 해주는 핵심적인 기술적 진보입니다.

3. 베라 루빈 데이터 처리 속도, HBM4로 날개를 달다
엔비디아의 베라 루빈 프로젝트는 수조 개의 매개변수(파라미터)를 가진 거대언어모델(LLM)과 같은 차세대 AI 모델의 훈련 및 추론을 목표로 합니다. 이는 실시간으로 상상조차 하기 힘든 방대한 양의 데이터를 GPU에 끊임없이 공급해야 함을 의미합니다. 바로 이 지점에서 HBM4가 핵심 엔진 역할을 수행하며 베라 루빈 데이터 처리 속도를 극대화합니다.
HBM4의 기여 메커니즘은 명확합니다. 11Gbps 이상의 초고속 데이터 전송 능력은 GPU가 한 번의 연산을 마친 뒤 다음 데이터를 기다리며 허비하는 유휴 시간(idle time)을 거의 ‘0’에 가깝게 줄여줍니다. 즉, GPU가 쉴 틈 없이 일하게 만들어 연산 효율을 100%에 가깝게 끌어올리는 것입니다. 이것이 바로 HBM4가 고질적인 메모리 병목 현상 해결에 직접적으로 기여하는 원리입니다. GPU의 잠재력을 마지막 한 방울까지 짜내는 열쇠가 바로 HBM4인 셈입니다.
엔비디아의 발표에 따르면, HBM4를 탑재한 베라 루빈 플랫폼은 기존 블랙웰 플랫폼 대비 동일한 AI 모델을 학습시키는 데 필요한 GPU의 수를 1/4로 줄일 수 있습니다. 이는 AI 연산에 들어가는 막대한 비용을 잠재적으로 1/10 수준까지 축소할 수 있음을 의미하며, AI 기술의 대중화를 앞당기는 중요한 계기가 될 것입니다.
특히 주목할 점은 HBM4가 ‘실리콘 포토닉스(Silicon Photonics)’ 기술과 결합될 가능성입니다. 실리콘 포토닉스는 기존의 전기 신호 대신 빛(광신호)으로 데이터를 전송하는 기술입니다. 이 기술이 HBM4와 결합하면, 데이터 전송 속도는 현재보다 10배, 전력 효율은 5배까지 향상될 수 있습니다. 이는 AI 데이터센터의 성능 한계를 다시 한번 뛰어넘는 혁신을 예고합니다. 2026년 하반기 베라 루빈 출시를 앞두고, 아마존, 구글 등 주요 클라우드 서비스 제공자(CSP)들은 이미 HBM4 샘플을 테스트하며 차세대 AI 인프라 준비에 박차를 가하고 있습니다. 특히 한국 시장에 우선 공급이 확정되어, 국내 AI 생태계 발전에도 긍정적인 영향을 미칠 전망입니다.

4. HBM4 탑재 AI 가속기: AI 연산의 패러다임을 바꾸다
현대 AI 연산에서 AI 가속기의 최종 성능은 GPU 코어의 순수한 계산 능력만으로 결정되지 않습니다. 그 강력한 코어에 얼마나 빠르고 끊김 없이 데이터를 공급하는가, 즉 메모리 대역폭이 성능을 좌우하는 핵심 변수가 되었습니다. 아무리 뛰어난 두뇌(GPU)를 가졌더라도, 정보를 전달하는 신경망(메모리)이 느리다면 제 역할을 할 수 없는 것과 같습니다.
HBM4 탑재 AI 가속기는 바로 이 신경망을 혁신하여 AI 연산의 패러다임을 바꾸고 있습니다. 대폭 확장된 메모리 대역폭을 통해 한 번에 훨씬 더 많은 데이터를 처리할 수 있어, AI 모델의 훈련 및 추론 속도를 이전과는 비교할 수 없는 수준으로 향상시킵니다. HBM4 베라 루빈 GPU는 이러한 혁신의 가장 대표적인 예시입니다. TSMC의 최첨단 3나노 공정으로 제작된 강력한 연산 코어와 HBM4의 초고대역폭이 결합하여 완벽한 시너지를 발휘합니다.
이러한 기술적 진보는 우리의 삶을 바꿀 구체적인 시나리오를 가능하게 합니다. 예를 들어, 자율주행차가 도로의 수많은 변수를 실시간으로 인식하고 판단하는 데 필요한 막대한 데이터 처리가 가능해집니다. 또한, 초거대 AI 모델이 실시간으로 외국어를 통역하고, 사용자의 의도에 맞춰 새로운 이미지를 창작하며, 신약 개발을 위한 복잡한 단백질 구조를 순식간에 분석하는 등 미래 AI 서비스 구현의 기반이 됩니다.
이러한 변화의 중심에는 치열한 기술 경쟁이 있습니다. 업계 동향은 다음과 같습니다.
- 엔비디아: AI 시장의 절대 강자인 엔비디아는 2026년 CES에서 베라 루빈 플랫폼을 공식 발표하고, 2027년부터 본격적인 공급을 시작할 계획입니다.
- SK하이닉스 & 삼성전자: 글로벌 메모리 시장을 이끄는 두 한국 기업은 HBM4 시장의 ‘퍼스트 벤더(First Vendor)’ 자리를 놓고 치열한 기술 경쟁을 벌이고 있습니다. 현재 초기 루빈 플랫폼 물량의 약 70%를 SK하이닉스가 점유할 것으로 예상되며, 삼성전자 역시 차세대 기술로 맹추격하고 있습니다.
이러한 선두 기업들의 치열한 경쟁은 HBM4 기술의 발전을 더욱 가속화하고 장기적으로 가격 안정화에 기여하여, 더 많은 기업과 개발자가 최첨단 AI 기술의 혜택을 누릴 수 있는 긍정적인 효과를 가져올 것으로 기대됩니다.
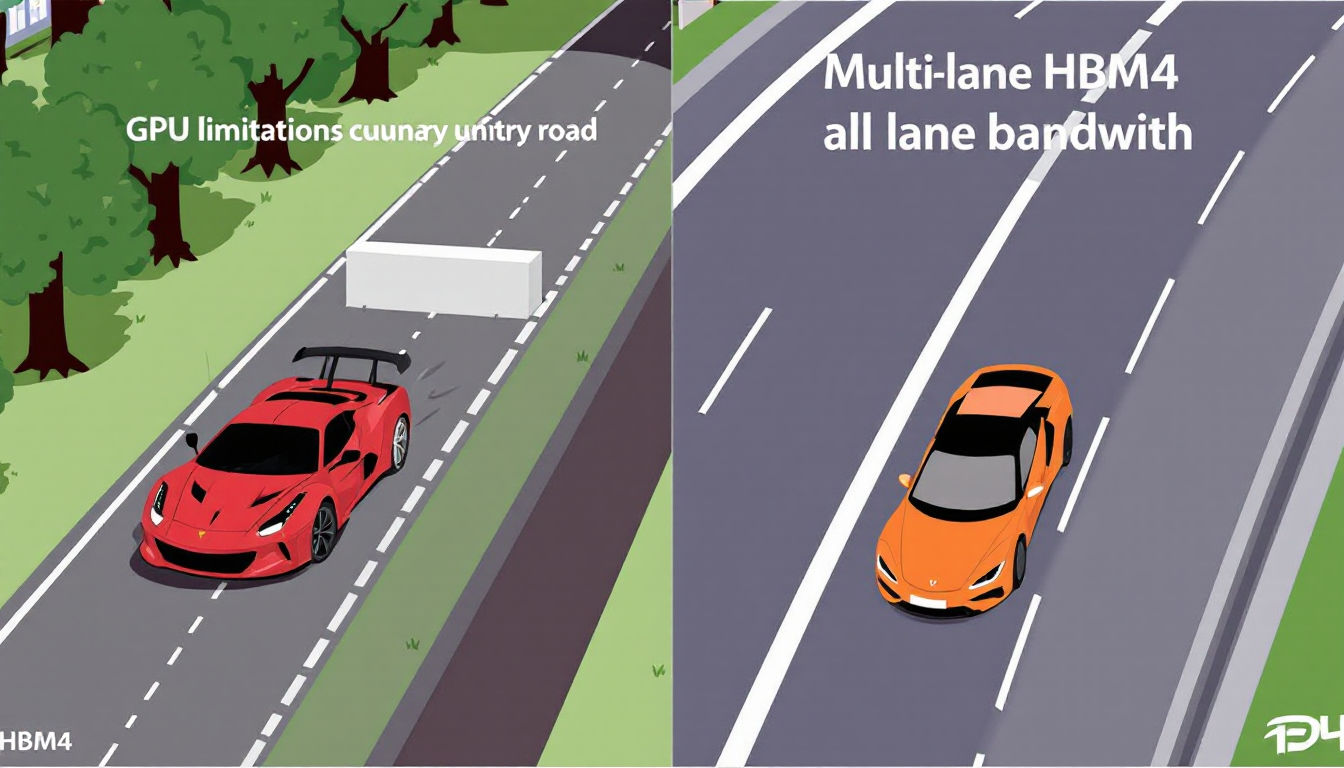
5. 고질적 문제, 메모리 병목 현상과 HBM4의 명쾌한 해법
메모리 병목 현상이란 무엇일까요? 이 개념을 쉽게 이해하기 위해 ‘세계 최고의 슈퍼카(GPU)가 좁은 시골길(메모리 대역폭)을 달리는 상황’을 상상해 볼 수 있습니다. 슈퍼카의 엔진이 아무리 강력해도 도로가 좁고 구불구불하면 결코 제 속도를 낼 수 없습니다. 이와 마찬가지로, GPU의 연산 능력이 아무리 뛰어나도 메모리가 데이터를 제때 공급하지 못하면 GPU는 데이터가 도착하기를 기다리며 멈춰 서게 되고, 이로 인해 전체 시스템의 성능이 크게 저하되는 현상이 바로 메모리 병목입니다.
특히 AI 작업처럼 방대한 데이터를 동시에 처리해야 하는 환경에서, 기존의 GDDR 메모리는 물리적인 데이터 전송로의 한계와 긴 지연 시간 때문에 병목 현상을 유발할 수밖에 없었습니다. AI 모델의 크기가 커질수록 이 문제는 더욱 심각해져, 값비싼 GPU 자원을 낭비하는 주된 원인으로 지목되어 왔습니다.
차세대 고대역폭 메모리인 HBM4는 이 문제에 대한 근본적이고 명쾌한 해결책을 제시합니다. HBM4는 D램 칩을 수직으로 높이 쌓아 데이터가 이동하는 경로를 수천 개로 늘립니다. 이는 앞서 비유한 ‘좁은 시골길’을 단숨에 ‘왕복 20차선 고속도로’로 바꾸는 것과 같습니다. 데이터가 이동할 수 있는 길이 압도적으로 넓어지면서 GPU는 더 이상 데이터를 기다릴 필요 없이 자신의 연산 능력을 100% 발휘할 수 있게 됩니다.
이를 통해 메모리 병목 현상 해결은 물론, 부가적인 이점까지 얻을 수 있습니다. 데이터가 이동하는 물리적 거리가 칩 내부로 매우 짧아지면서, 데이터 전송에 필요한 전력 소모까지 크게 줄어듭니다. 즉, 성능은 높이고 에너지 소비는 줄이는 일석이조의 효과를 얻는 것입니다. 이는 대규모 서버를 운영하는 데이터센터의 운영 비용 절감에도 직접적으로 기여하는 중요한 장점입니다. HBM4는 단순히 속도만 빠른 메모리가 아니라, 컴퓨팅 시스템의 구조적 비효율을 해결하는 스마트한 솔루션입니다.

6. 미래 전망: HBM4 이후의 메모리 시장과 기술 발전 방향
AI 시장의 폭발적인 성장에 힘입어 HBM 시장은 2026년 이후에도 강력한 ‘슈퍼사이클’을 이어갈 것으로 전망됩니다. HBM4 베라 루빈의 등장은 이러한 성장의 기폭제가 될 것입니다. SK하이닉스가 HBM4 초기 시장의 70%를 점유할 것으로 예상되고, 삼성전자가 평택 4공장 가동을 통해 생산 능력을 확대하는 등, 공급망 확대를 위한 기업들의 발 빠른 움직임이 이를 증명합니다.
차세대 고대역폭 메모리 기술의 활용 분야 또한 더욱 넓어질 것입니다. 현재는 AI 데이터센터와 고성능 컴퓨팅(HPC) 분야가 주요 시장이지만, 앞으로는 스마트폰이나 노트북에서 AI 연산을 수행하는 ‘온디바이스 AI’, 그리고 첨단 운전자 보조 시스템(ADAS)과 자율주행차 분야로까지 그 영향력이 확산될 가능성이 높습니다. 더 작고 효율적인 HBM이 개발되면서 우리의 일상과 더 가까운 곳에서 그 기술을 체감하게 될 것입니다.
향후 메모리 기술은 다음과 같은 방향으로 발전할 것으로 예측됩니다.
- 전송 속도 고도화: 현재 11Gbps 이상인 전송 속도를 15Gbps, 20Gbps까지 더욱 높이기 위한 연구개발이 이미 진행 중입니다. 이는 AI 모델의 학습 시간을 더욱 단축시킬 것입니다.
- 광학 기술과의 융합: 실리콘 포토닉스와 같은 광통신 기술을 메모리 패키지에 직접 통합하여 전기 신호의 물리적 한계를 극복하려는 시도가 가속화될 것입니다. 이는 데이터 전송의 속도와 효율을 다시 한번 혁신할 '게임 체인저' 기술입니다.
- 맞춤형 HBM의 등장: 특정 AI 연산에 최적화된 간단한 연산 로직을 HBM 내부에 통합하는 ‘PIM(Processing-in-Memory)’ 기술이 차세대 격전지가 될 것입니다. 이는 메모리가 단순한 데이터 저장소를 넘어, 연산의 일부를 직접 처리하는 능동적인 역할을 수행하게 됨을 의미합니다.
IT 기술에 관심 있는 독자라면 엔비디아의 차기 플랫폼인 '루빈 울트라(Rubin Ultra)', SK하이닉스와 삼성전자가 개발 중인 차세대 HBM4-PIM 제품, 그리고 인텔과 AMD가 선보일 HBM 탑재 차세대 AI 가속기 등의 기술 동향을 주목할 필요가 있습니다.

7. 결론: HBM4 베라 루빈, AI 혁신을 위한 필수불가결한 선택
지금까지 우리는 HBM4 베라 루빈이 가져올 AI 시대의 혁신적인 변화에 대해 다각도로 살펴보았습니다. 결론적으로, HBM4 베라 루빈은 단순히 더 빠른 메모리 부품이 아닙니다. 이것은 고질적인 메모리 병목 현상 해결을 통해 베라 루빈 데이터 처리 속도를 극대화하고, HBM4 탑재 AI 가속기의 잠재력을 100% 끌어내는, AI 산업의 패러다임 전환을 이끄는 핵심 기술입니다.
AI 효율을 4~5배 증대시키고 운영 비용을 획기적으로 절감하는 이 기술은, 2026년 이후 AI 인프라의 경쟁력을 좌우할 필수불가결한 요소가 될 것입니다. 어떤 기업이 HBM4 기반의 AI 인프라를 먼저 확보하고 최적화하는가에 따라 AI 시장의 판도가 달라질 수 있습니다. 이는 더 이상 선택의 문제가 아닌, 생존과 성장을 위한 필수 전략이 되었습니다.
IT 전문가, 소프트웨어 개발자, 그리고 미래 기술 트렌드에 관심 있는 모든 독자 여러분께서는 HBM4 기술 동향과 시장 변화를 지속적으로 주시해야 합니다. 오늘 이 글에서 소개된 정보가 다가올 AI 시대의 거대한 기술적 변화를 이해하고, 각자의 분야에서 미래를 준비하는 데 든든한 기반이 되기를 바랍니다. HBM4 베라 루빈이 열어갈 새로운 AI의 지평은 이미 우리 눈앞에 펼쳐지기 시작했습니다.
자주 묻는 질문 (FAQ)
Q: HBM4 베라 루빈은 기존 HBM3 대비 어떤 점이 가장 크게 개선되었나요?
A: HBM4는 HBM3 대비 데이터 전송 속도가 11Gbps 이상으로 22% 이상 향상되었으며, 최대 적층 수가 16단 이상으로 늘어나 용량이 커졌습니다. 또한, 인터페이스가 1024-bit에서 2048-bit로 두 배 확장되어 데이터 처리량이 크게 증가했습니다.
Q: HBM4가 메모리 병목 현상을 해결하는 핵심 원리는 무엇인가요?
A: HBM4는 D램 칩을 수직으로 높이 쌓아 데이터가 이동하는 경로를 수천 개로 늘려 대역폭을 압도적으로 넓힙니다. 이는 GPU가 데이터를 기다리지 않고 연산 능력을 100% 발휘할 수 있도록 하여, 데이터 공급 지연으로 인한 성능 저하(메모리 병목)를 근본적으로 해결합니다.
'IT' 카테고리의 다른 글
| 2026 AI 기본법 주요 내용과 EU AI Act 비교 완벽 총정리 (13) | 2026.01.31 |
|---|---|
| 베라 루빈 한국 우선 공급과 엔비디아 AI 전략 완벽 분석 (21) | 2026.01.29 |
| 반복 업무 탈출! Notion AI로 스마트하게 일하는 5가지 방법 (15) | 2025.09.17 |
| AI 시대, 당신의 직업은 안전한가요? 상위 1%만 아는 AI 역량 강화 비법 3가지 (37) | 2025.09.14 |
| 이커머스/마케팅 실무자를 위한 Nano Banana 활용 가이드 (feat. ROI) (49) | 2025.09.08 |



